Qualitative Case Studies for Assessing Foundation Models
Ahmed Abdulaal, Hugo Fry, Ayodeji Ijishakin, Nina Montaña Brown
Introduction
There are numerous quantitative metrics used to evaluate machine learning models. These metrics provide a numerical assessment of a model's performance on specific tasks. However, they often fail to capture the full spectrum of a model's capabilities and limitations.
In contrast, qualitative assessments can provide deeper insights into a model's behavior, decision-making processes, and potential biases. By examining case studies and real-world applications, researchers can identify strengths and weaknesses that may not be apparent through quantitative metrics alone.
In this article we present several case studies that illustrate various aspects of model performance, and allow for a more nuanced understanding of the current state of radiological foundation models.
Disclaimer
A small number of case studies are presented here for illustrative purposes. By definition, these case studies cannot be exhaustive and therefore do not represent the full range of model capabilities or limitations. The intention is to highlight specific examples that demonstrate the importance of qualitative assessment in evaluating foundation models.
Experimental Setup
We focus here on Chest X-Ray (CXR) interpretation, a common and well-studied application of foundation models in radiology. We use two datasets for this analysis. The first dataset is split into a standard train/val/test split. The second dataset is a fully external, held-out test set that was not used during model training and does not derive from the same centres as the first dataset. This external dataset allows us to assess the generalizability of the models to new, unseen data.
Our system, Mecha Net XR, is trained on the train split of the first dataset. All case study cases are then based on the external test set. We compare Mecha Net XR's performance to several state-of-the-art generalist and radiology-specific models. We also include the report written by a radiologist for each case as a reference standard. For cross-sectional, single study, single series cases, we simply ask the models to generate a structured report in the prompt. For multi-view and/or multi-study imaging, we match the prompt as closely as practicable, given the models' input limitations (see Appendix for full prompt details).
We provide three case studies below.
Case Studies
Here we present three case studies that highlight different aspects of model performance in chest X-ray interpretation. Each case study includes the model outputs, the radiologist's report, and a discussion of the findings.
Case Study 1
A portable chest X-ray for a patient with chest pain. We must comment on bilateral pleural effusions, a PICC line, and mild cardiomegaly.
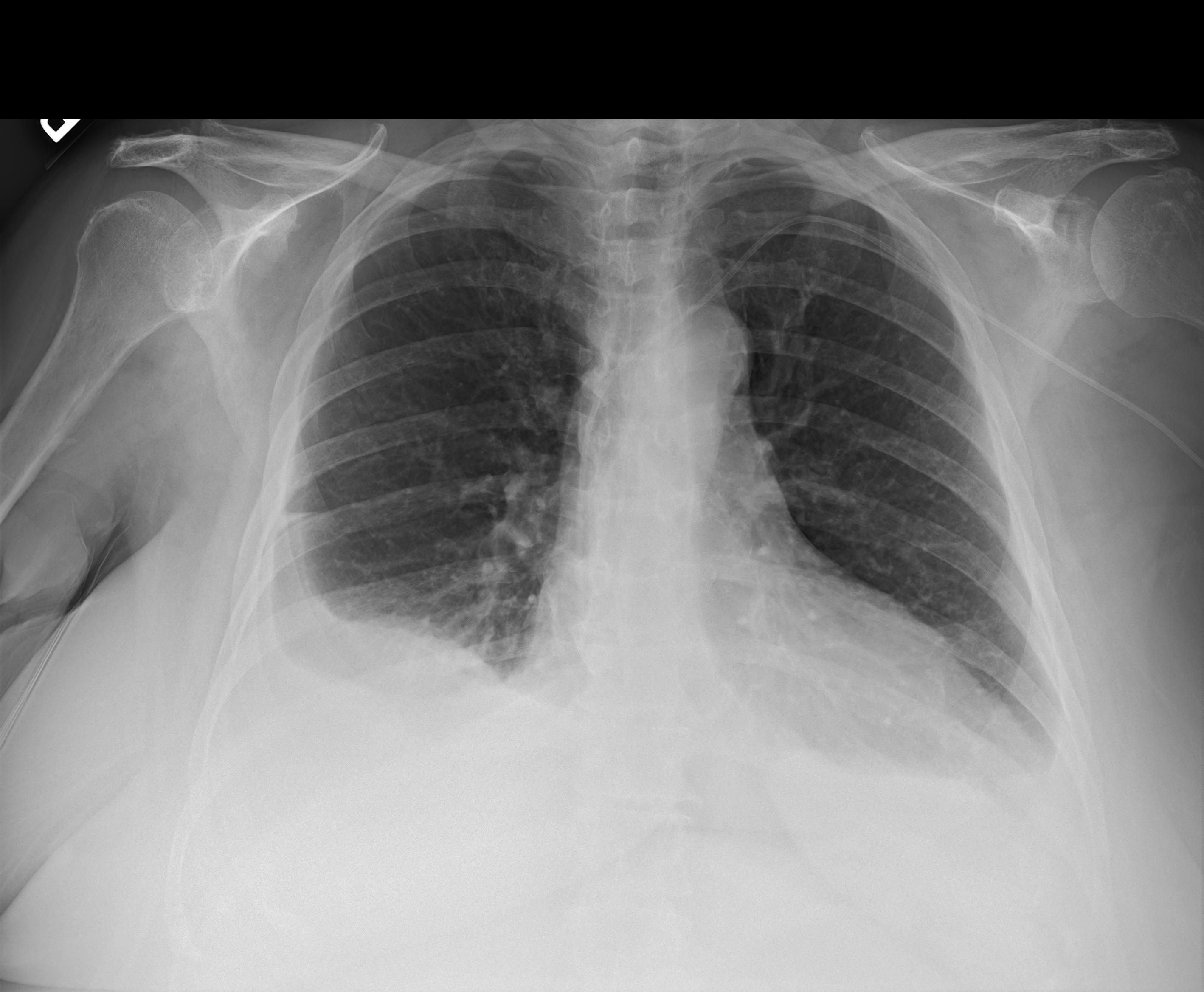
Mecha Net XR correctly identifies bilateral effusions and PICC placement, but misses the mild cardiomegaly. Harrison R.1 hallucinates lung collapse/atelectasis not present in the study, misses the left pleural effusion entirely, and incorrectly reports normal heart size. GPT-5.1 fails most significantly: it misses the bilateral pleural effusions completely, fabricates atelectasis and elevated hemidiaphragm, and misses the cardiomegaly. Gemini 3 Pro misses the left pleural effusion completely, is noncommittal on cardiomegaly, and speculatively raises consolidation/atelectasis not supported by the radiologist's interpretation.
Case Study 2
Comparing current PA and lateral views against a prior portable study. Can models track interval change in a worsening pleural effusion?
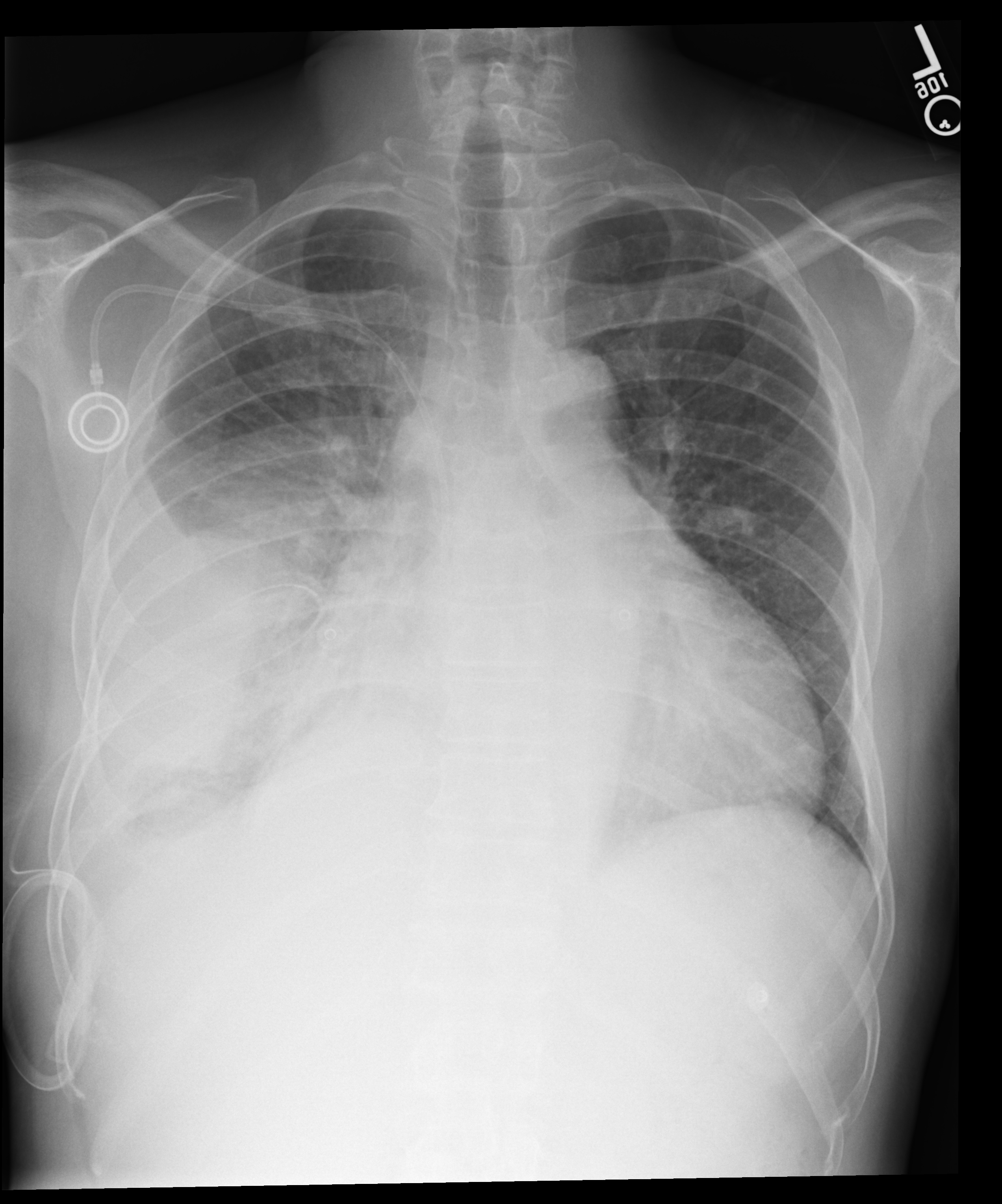
This multi-view, multi-study case reveals significant limitations in current foundation models. Harrison R.1 failed entirely on this particular set of images with the given prompt. Mecha Net XR identified all key findings including the worsening effusion, both devices, atelectasis, and clear left lung, though it doesn't explicitly mention cardiomegaly (instead noting a "stable" silhouette). GPT-5.1 correctly identifies the interval increase but describes the "mild interstitial prominence" as stable which is contentious as it could be argued this has in fact worsened. Most critically, Gemini 3 Pro gets the temporal comparison backwards, calling the effusion "stable to slightly decreased" when the radiologist clearly states it has "increased", a clinically dangerous error. Gemini correctly describes the "resolution of subcutaneous emphysema", which whilst correct is missed by the human radiologist.
Case Study 3
An intubated ICU patient with three support devices. Missing an endotracheal tube or nasogastric tube isn't a minor oversight here.
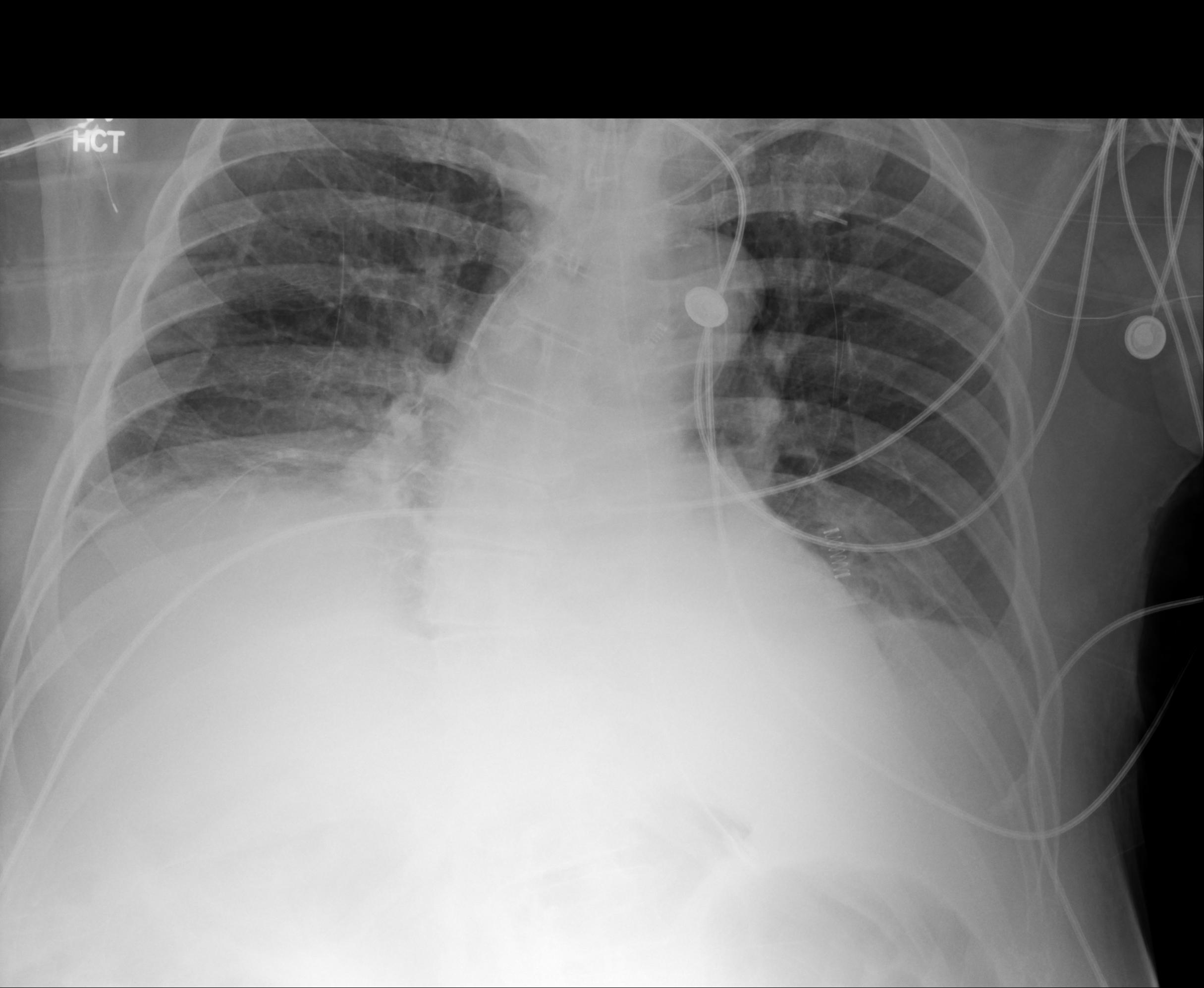
This ICU case tests tube/line identification. Mecha Net XR correctly identifies all three support devices, their positions, low lung volumes, atelectasis, and possible small effusions. Harrison R.1 identifies most devices but misses the possible pleural effusions and reports the ETT tip "at the carina." GPT-5.1 correctly notes low lung volumes and atelectasis but misses the ETT and NGT, and overstates effusion size as "moderate to large" versus the radiologist's "small." Gemini 3 Pro misses the ETT and NGT and similarly overstates severity.
Conclusion
These case studies reveal a consistent pattern: state-of-the-art generalist models struggle with fundamental radiological tasks. Missed pleural effusions, fabricated findings, incorrect laterality, and, occasionally, failure to identify support devices like endotracheal tubes.
Mecha Net XR performed well across these examples, closely matching radiologist interpretations in most instances. We're encouraged by these results, though we recognize that three case studies cannot capture the full complexity of clinical practice. Every model, including ours, will have failure modes that only emerge at scale.
The broader lesson here extends beyond any single system. Quantitative benchmarks like AUC scores, F1 metrics, accuracy percentages provide valuable signal but can obscure critical weaknesses. A model might achieve impressive aggregate performance while still hallucinating findings, missing obvious pathology, or getting temporal comparisons backwards.
As foundation models increasingly enter clinical workflows, this kind of rigorous, case-by-case scrutiny becomes essential. The path forward requires both: robust quantitative evaluation and careful qualitative analysis that asks not just "how often is the model right?" but "when it's wrong, how wrong is it? And "what can we do about it?"
Despite the need for careful evaluation and ongoing improvement, it is very clear to us that foundation models will improve patient care by hugely accelerating workflows and reducing diagnostic errors.
If you would like to cite this work, please use the following BibTeX entry:
@misc{mecha2025qualitative,
author = {Ahmed Abdulaal and Hugo Fry and Ayodeji Ijishakin and Nina Montaña Brown},
title = {Qualitative Case Studies for Assessing Foundation Models},
year = {2025},
month = {November},
url = {https://mecha-health.ai/blog/Assessing-models-qualitatively},
note = {Case studies demonstrating the importance of qualitative assessment in evaluating radiological foundation models}
}
Appendix
For Case Study 2, which involves multi-view and multi-study comparisons, we used different prompts depending on each model's input capabilities. Expand the sections below to view the prompts.
Ready to transform your radiology workflow?
Experience next-generation foundation models that revolutionize radiology reporting. Join leading healthcare institutions partnering with us to deploy cutting-edge AI that transforms patient care.